Big Data and Data Science are the thriving areas that are disrupting the way we do business and make decisions. Extremely large amounts of data that are available nowadays, bring new possibilities that did not exist ever before. Hence, it is crucial to understand their role and, having the perspective of well-established database and Business Intelligence solutions, decide on the best set of tools for a given setting.
The Inception: Relational Databases
According to different dictionaries, data refers to facts and statistics collected together for reference or analysis. Data is turned into actionable knowledge only once it is processed either by computer algorithms or human analysts. Nowadays, data is primarily stored in digital format and handled using computers. Hence, with technological advancements the amounts of available data have also significantly increased, emphasizing the importance of data management and analytics. Initially, data was handled with a file system. However, the rapid development of computer systems imposed the need for a more complex, standardized, and stand-alone solution.
Over many years, relational database systems (RDBMSs) became a de facto standard for managing data. Thanks to the intuitive data organization within tables and comprehensive database engines, RDBMSs quickly gained more and more users. Once data is represented with a database schema, the database engine exploits a well-defined relational algebra to enable data handling on a high abstraction level (i.e., using SQL) and ensures the accuracy and consistency of data. SQL, as a declarative language, removes the burden of users writing procedural code and, instead, a database engine provides query execution plans to retrieve the necessary data. SQL includes both Data Description Language for the creation of data structures, as well as Data Manipulation Language that is used for the querying, insertion, updating, and deletion of data. Importantly, RDBMSs provide ACID properties:
- Atomicity – each transaction as a single unit needs to completely execute or fail
- Consistency – every transaction results in a valid database state satisfying all related constraints
- Isolation – concurrency control
- Durability – ensuring the persistence and the recovery of data
Evolving to Analytical Processing: BI and Data Mining
Ensuring ACID properties is computationally expensive, especially in the context of having transactions and data analysis performed in parallel over the same database. This led to the rise of the Business Intelligence area that focuses on data analytics. Here, data from typically internal and controlled data sources are periodically extracted, transformed, and loaded into a data warehouse. Data warehouses can store current and historical data which is organized to facilitate the analysis. In this context, data should conform to the star-schema comprising of the analysis perspectives called dimensions, and the data being analyzed as facts containing measures. Such data structuring is also known as data cube, and it is the foundation for On-Line Analytical Processing (OLAP) where data cube can be navigated with OLAP operations such as Slice, Dice, Roll-up, and Drill-down. Many data warehouses and OLAP solutions build on top of RDBMS, thus representing data cube with tables.
Another kind of analysis performed over data warehouse and other types of data stores is Data Mining which has a goal of discovering patterns in data sets. Data Mining is an interdisciplinary subfield of computer science and statistics which involves different classes of tasks including anomaly detection, association rule learning, clustering, classification, regression, etc. While OLAP solutions typically provide user-friendly and intuitive interfaces for non-technical users, Data Mining requires a relatively high level of technical knowledge, both to apply the algorithms and to interpret the result.
Managing Big Data
Not everything is a table and not everything has a predefined schema. The massive data generation originating from social networks, mobile devices, sensors, and other data sources raised challenges that motivated the creation of novel tools and techniques. Initially, Big Data was characterized by 3 Vs – volume, variety, and velocity. Thus, enormous volumes of different and fast-growing data challenged the RDBMSs that do not scale easily due to ACID properties and fixed schema requirements. Many new Vs have emerged since then, such as data variability, veracity, value, etc. This caused the creation of new tools and frameworks that have the purpose of addressing one or more of the novel challenges. Examples of these new tools include:
- Hadoop – a distributed storage and processing framework
- Spark – a cluster-computing framework
- Cassandra – a distributed NoSQL database management system
- Zookeeper – a centralized service for cluster management
- Elastic Search – a search engine, etc.
Most of these tools can map to one or more elements of traditional database management systems. Here, it became essential to understand the purpose of each tool/framework and know how to combine them into a single architecture. Moreover, requirements for ACID properties need to be considered depending on each tool or framework.
Next Generation Analysis: Data Science
While Big Data focuses on providing tools and techniques for managing and processing large and diverse quantities of data, it is not as focused on interpreting the data processing results to support decision making. This is where the area of Data Science continues and focuses on using advanced statistical techniques to analyze Big Data and interpret the results in a domain-specific context. Thus, Data Science implies an intersection of various areas including:
- (Big) Data Engineering
- Statistics
- Advanced Computing
- Visualization
- Domain Expertise and others
In this context, it requires tools and frameworks for:
- Statistical programming
- Databases
- Importing and Cleaning of Data
- Exploratory Data Analysis
- Machine Learning
- Deep Learning
- Text Mining
- Natural Language Understanding
- Recommender Systems, etc.
Overall, Data Science focuses on providing an end-to-end solution for gaining valuable insights to support decision making in this fast and heterogeneous context of modern data management and analytics.
Current Landscape: Data Lakes
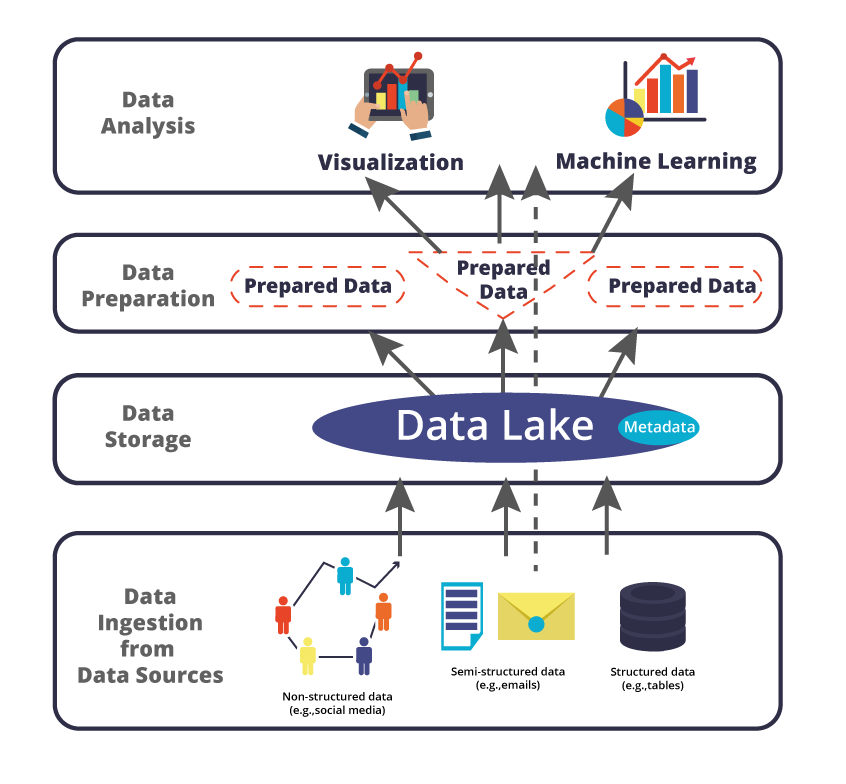
Thanks to social networks, personal mobile gadgets, sensors, and other data-intensive application and devices, even small-and-medium enterprises got the opportunity to obtain large volumes of data about their business and customers. Here, Data Lake rose as a typical solution for managing and analyzing Big Data in such a context. As illustrated in the figure below, when having heterogeneous data sources including non-structured (e.g., social media) and/or semi-structured (e.g., email) data, Data Lakes (typically an HDFS-based solution) presents a flexible data management solution where data can be ingested. Ideally, Data Lake should also include a metadata layer that describes the data organization and semantics (e.g., by using semantic technologies). Once gathered and stored, data can optionally be prepared (e.g., by creating tables and/or matrices) for data analysis (e.g., Visualization or Machine Learning techniques). Finally, using the data lake supports data processing in the batch mode (following the full arrows), i.e., the data is stored and then processed to support reporting, and it can also be coupled with the components for data stream processing (following the doted arrow) where data can be directly processed to support real-time analysis.
Keeping up with trends is always hard in the ever-evolving computer software world. No matter what the business focus is, being competitive is no longer a matter of “just” delivering a product or service but a race to provide the ultimate user experience to your segment of the market. Thus, having a deep understanding of the data your organization can obtain from multiple sources and leveraging the potential it has to boost your business is the key to compete and evolve.